
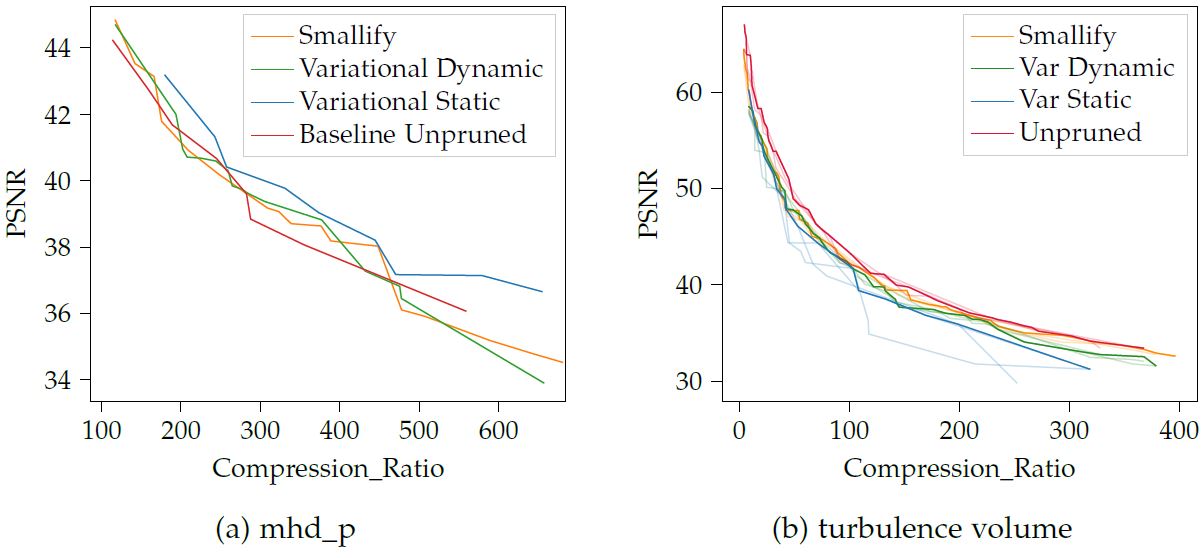
Analysis of compression quality of Neurcomp with and without pruning. Network architecture search is performed to generate good parameterizations for the network and pruning algorithms. The pareto frontier of this search is then plotted.
Despite the fact that the pruning algorithms can surpass the unpruned baseline, it is not possible to make a conclusive evaluation on whether pruning is advantageous for Neurcomp due to the significant variance in the data and the relatively minor quality improvements.
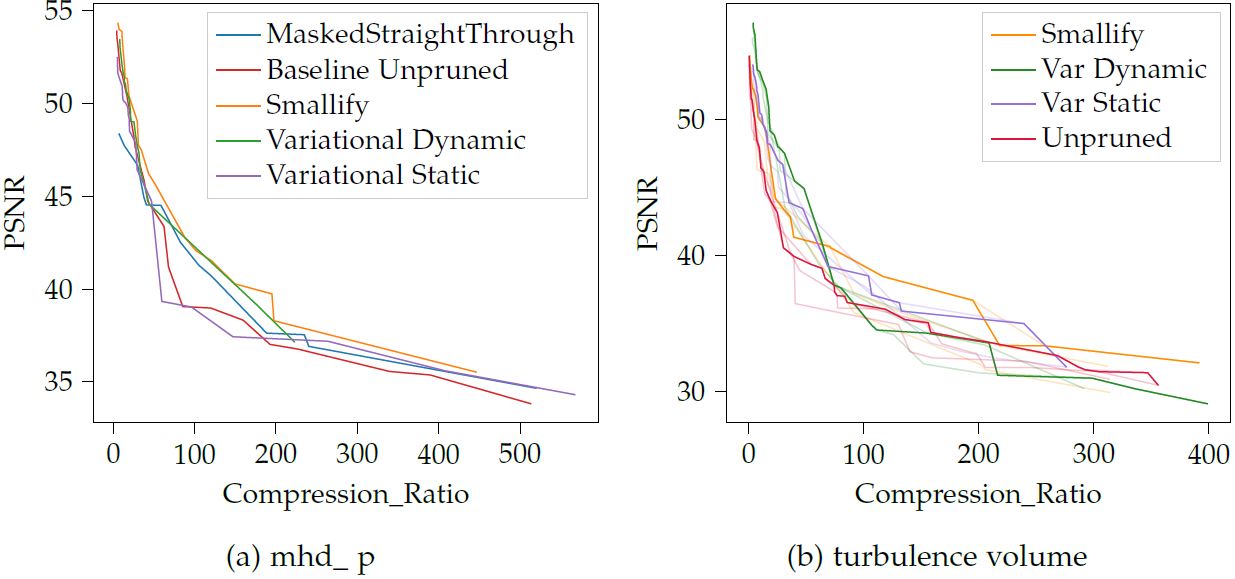
Analysis of compression quality of fV-SRN with and without pruning. Network architecture search is performed to generate good parameterizations for the network and pruning algorithms. The pareto frontier of this search is then plotted.
Although significant variance is present in the data, the pruning algorithms are effective at increasing the compression quality and consistently outperform the unpruned baseline.
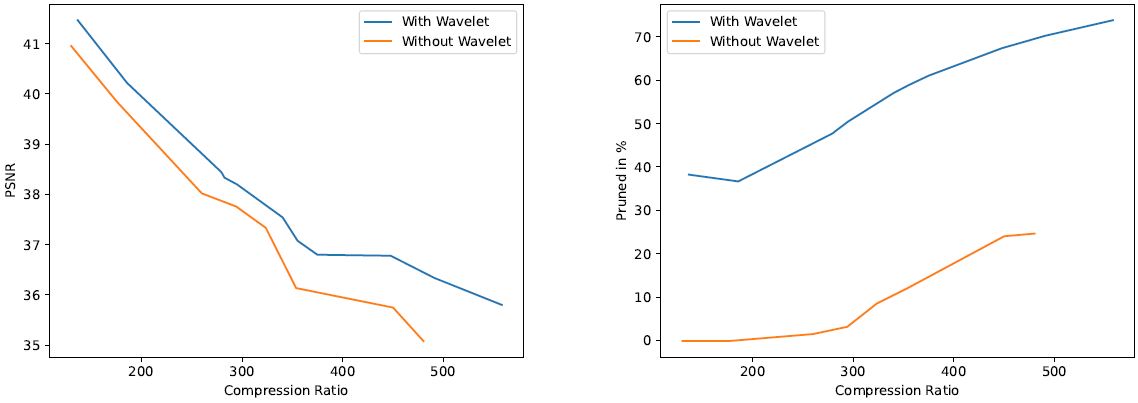
Comparison of pruning effectiveness on the fv-SRN, when the feature grid is represented in the frequency domain or spatial (without wavelets). Here, variational dropout in regard to its overall quality-compression ratio (left figure) and amount of pruning performed (right figure).
In the time-frequency domain of the wavelet transformation, most information of the original feature grid is summed up in a few wavelet coefficients, enabling the pruning algorithms to more efficiently distinguish between important and unimportant parameters to the reconstruction task. This results in significantly higher pruning and also higher compression-quality ratio.